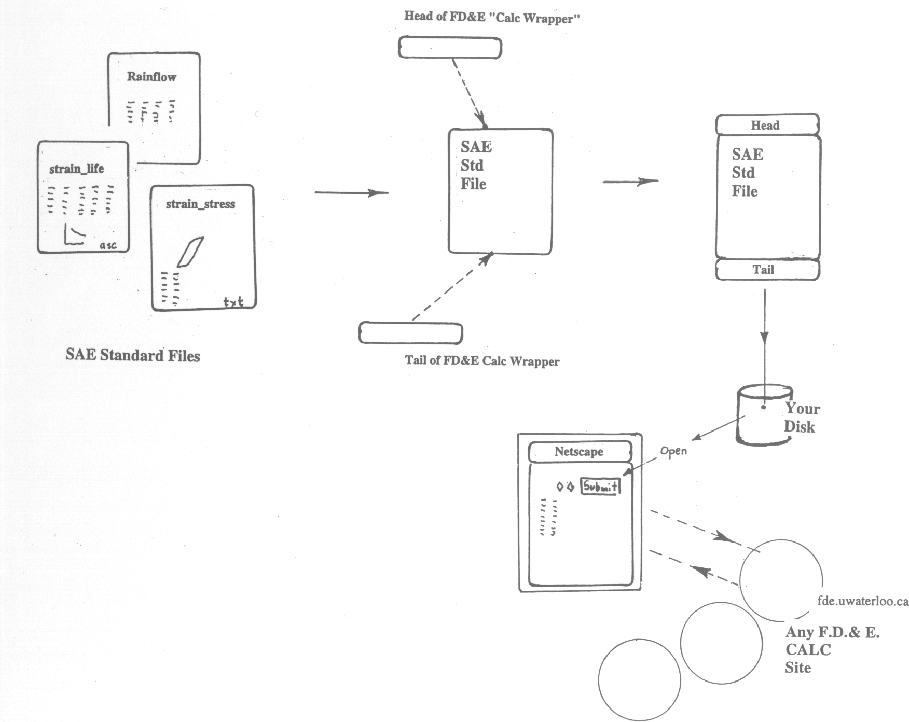
If one takes another step and assumes that not only the problem
input
files, but also the output files from the cgi sites, have a standard
format, one can then "plug" the results into another problem and
repeat the process. Thus we could have a standard "raw" data
strain-life fatigue file that is sent to a cgi calc site, is
reduced and comes back as the common 6 or 7 strain-life fatigue
parameters, or a "fitted" digital curve, and is then sent to
another program that uses it and a rainflow file to
compute life. In a rough analogy one could compare the raw
strain-life file to a "problem-bolt". Our problem-bolt gets sent
to a calc site and returns as a "solution-bolt". In the meantime
a raw time history (problem-nut) is sent to a cgi site and
returns as a rainflow file or
"solution-nut". When they have both returned, along
with possibly a Kt/FEA description ("solution-washer?"), the whole
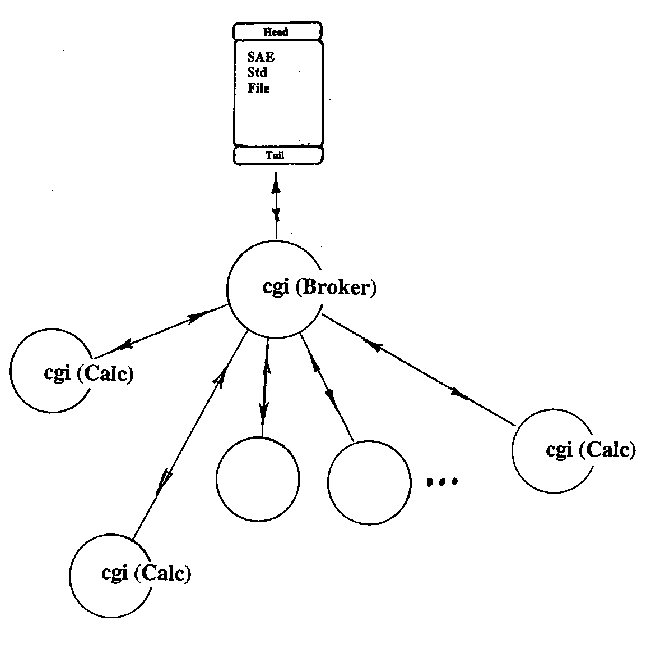
thing gets re-assembled into a solution-prediction. This might
then be returned to the originator/broker who is assembling a whole
bunch of FEA predictions etc. etc.
As long as a given problem is big enough to warrant the effort,
and decomposible into smaller segments,
the method may be worthwhile. This type of feature may require
inventing some sort of problem identification tag for files, e.g.:
#pit= /leftside/front/assembly102/part15/bolt1
which would require another addition to the standard file description.
{kind=link}
{kind=link}